

文|AI报道
2009年8月,新浪微博正式上线。经过近10年发展,截至去年12月,微博月活跃用户数已增至4.62亿,成为全球第 7 家活跃用户规模突破 4 亿的社交产品。
近日,话题#2000亿条微博被国家图书馆保存#上了微博热搜,一时间引起网友广泛关注和讨论。原来,国家图书馆互联网信息战略保存项目本月19日在北京启动,新浪成为首家互联网信息战略保存基地。因此,新浪网发布的新闻和微博上公开发布的博文,都将被国家图书馆保存。
微博大数据被国图保存,大家怎么看?
截至2018年12月,微博全站发布博文超过2000亿条、图片500亿张、视频4亿个、评论和赞总量近5000亿。新浪网和微博上新发布的内容,也将持续保存。对此,不少网友表示:我的微博也进历史了!
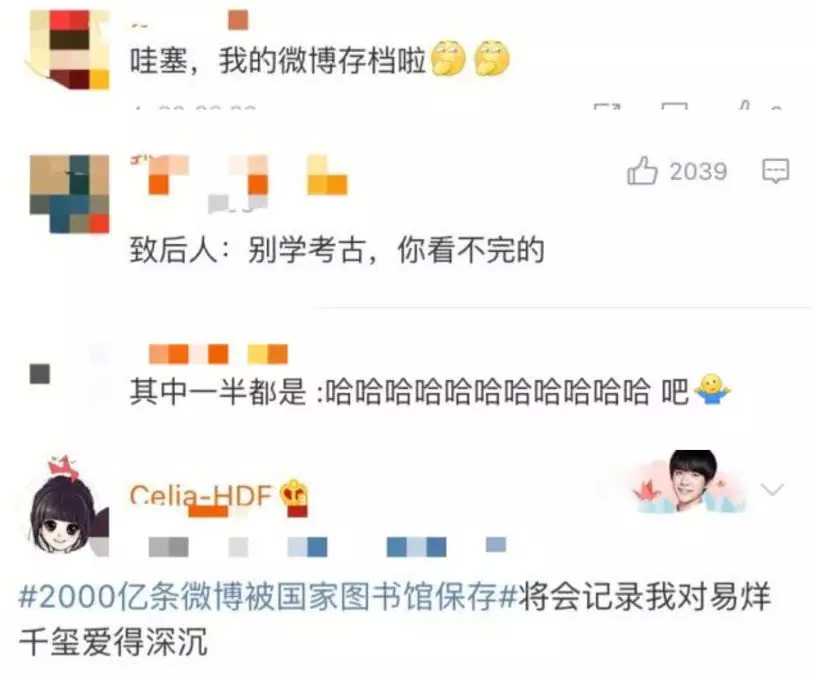
还有不少网友调侃:后代人看不懂我们的微博咋办......
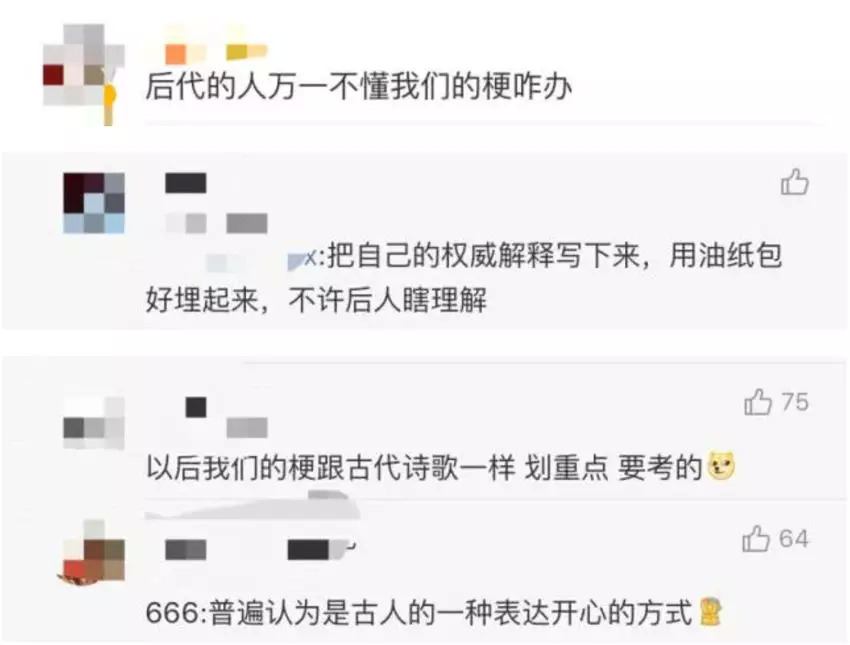
也有不少网友对此项目表示支持!
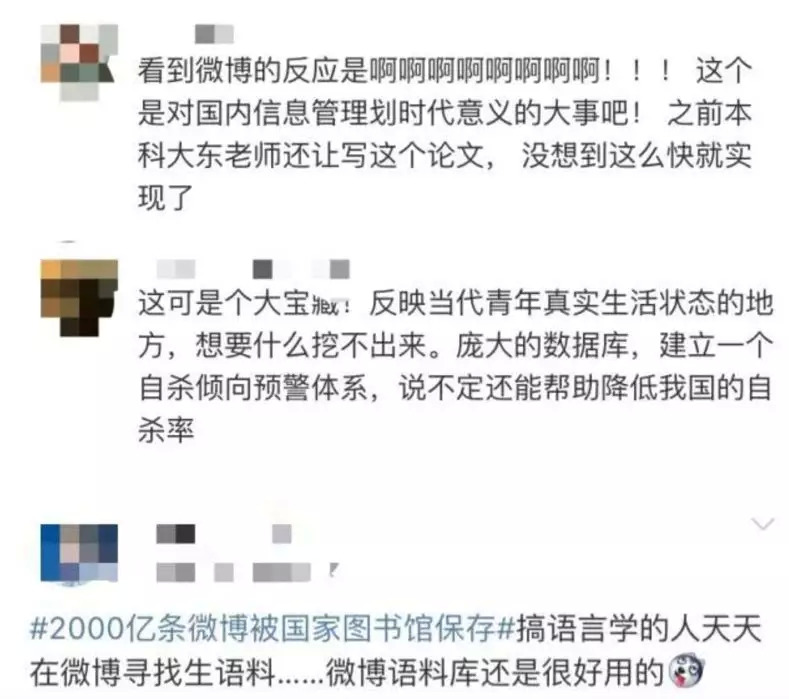
同时,还有人质疑,这样的行为是否侵权?

对此,有网友回应:“微博运营方对微博内容享有使用权。”
其实,建设互联网信息保存基地,国际上早就有先例。2010年,Twitter向美国国会图书馆捐赠推文数据的消息就引起了业界的广泛关注。根据美国国会图书馆与 Twitter当时发布的协议约定,Twitter将捐赠从其成立到协议日期的所有公开推文。

按照此协议,美国国会图书馆可以把在 Twitter上发布六个月后的任何内容提供给“真正的”研究人员。研究人员必须签署禁止商业用途以及内容重新分配的“通知”。图书馆不得以易于下载的形式在其网站上提供大部分内容。
事实上,很多国家都在开展互联网信息存档工作。国家图书馆数字资源部副研究馆员敦文杰介绍,国际上已完成或正在推进的相关项目大约有100多个。尤为值得一提的是,1996年在美国成立的非盈利机构Internet Archive在推动国际互联网信息存档起到了重要作用。该机构为互联网信息存档开发的采集和回放工具被业界广泛采用,推动制定相关技术的国际标准。
建设互联网信息保存基地能阻止“数字黑暗时代”吗?
早在2015年,互联网数据传输协议的缔造者之一,谷歌副总裁温特·瑟夫(Vint Cerf)曾经抛出一个令人为之一颤的疑虑:随着数字技术的不断迭代演化,今天人类保存在互联网上的图片、文档、文件等信息可能彻底丢失,在进入一个“数字黑暗时代”后,未来的人类可能根本没有关于21世纪的历史记录。

无需赘言,温特·瑟夫对于“黑暗时代”的隐喻,在现实中曾经真实的发生在中世纪早期的西欧。在这一时期,古罗马文明被战争破坏,万幸的是,在战争夹缝中生长起来的教会,保存了大量古罗马的文字,哲学、制度、法律、司法等文明的火种,成为整个西罗马帝国坠毁后幸存的“黑匣子”。而温特·瑟夫担心的,是当互联网成为人类文明和社会记忆的新载体,未来的人类,能否找到21世纪的“黑匣子”。
这种担忧不无道理。从甲骨文算起,到把文字落于纸上,再到印刷术与工业影像,一代有一代信息之体。最新一代就是互联网,而相较于书本文明,信息边际成本的大幅降低,让互联网信息规模呈指数级增长。不夸张地说,如今每天诞生的数据量,大概相当于人类从公元元年至大约一千年产生数据的总和。
信息的爆炸式增长,也让互联网的记忆被迅速遗忘。对此,《纽约客》的一篇文章曾写道:如今网页的平均寿命大概为100 天;哈佛法学院2014年的一项调查也显示,“《哈佛法律评论》和其他期刊中有超过70%的链接已经不再指向最初引用的信息,美国最高法院意见中的这一比例也达到50%。”
信息的遗失不止于公共记忆,每个人的私家互联网记忆,也可能因为平台的消亡而消亡。“当MySpace,GeoCities和Friendster都已经改头换面或被迫出售时,数以百万的账号被先后删除。”但纵然如此,许多人仍对“数字黑暗时代”的到来持怀疑态度。而事实上未来也并没有温特瑟夫描述的那般暗黑,因为在打捞互联网“记忆碎片”这件事上,人类正在凝聚难得的共识。
互联网的记忆,如何留存?
互联网信息是人类文明和社会记忆的新载体,客观反映了一定时期内政治、经济、文化和社会等方面的变迁。其易逝性和不可再生性,使互联网信息的采集和保存尤为迫切。
对信息的留存,许多机构在做系统性的努力。早在1996年的美国,设立伊始的“互联网档案馆”(Internet Archive)就致力于实现全球互联网信息的收集,存储和获取,至今已收集了大量的网页,视频,音频,软件和电子书,还收录了超过3510亿个网页。
2003年,12个国家机构还共同成立国际互联网保存联盟(IIPC),中国国家图书馆也在2007年加入。除了非营利组织,科技公司也希望将自己创造的海量信息,变成某种集体记忆。比如,Twitter上的部分推文(譬如涉及美国政策变化等公共事件),就会被收录到美国国会图书馆。
在中国,从2003年起,国家图书馆就开始采集和保存互联网资源。此次开启互联网信息战略保存项目,旨在建设覆盖全国的分级分布式中文互联网信息资源采集与保存体系,通过与国内重点数字文化生产和保存机构的合作,推动互联网信息的社会化保存与服务,构建国家互联网信息资源战略保障体系。

国家“十三五”战略规划就明确指出,要加快推动数据资源共享开放和开发应用,助力社会治理创新,深化政府数据和社会数据关联分析、融合利用,提高宏观调控、市场监管、社会治理和公共服务精准性和有效性。
然而,保存数字记忆,并非一桩易事。尤其伴随移动互联网时代的到来,信息被散落在一座座“孤岛”之上,也正因如此,任何机构都无法自包自揽,必须自下而上地调动社会力量。这也是为什么在互联网信息战略保存项目中,任何在中国境内开展互联网业务并在相关领域处于领先地位的企业机构,都可以申请成为互联网信息战略保存基地共建主体。信息数据也将由共建主体保存,国图会与共建主体联合进行分析,服务于政策决策,学术研究等非商业用途。
我们有理由相信,国家图书馆这次发起的创新的社会化存储方式,将让这些碎片化的数据资料得到最大价值的保存和使用,除了拥有当下的社会价值,也为后人提供了重新审视历史的机会。因为在某种意义上,每个时代信息的传播与存储能力,会在潜移默化中影响后人的历史观。
