来源:OpenAI 编辑:肖琴、小潘
推动人工智能发展的因素有三个:算法创新、数据(可以是有监督的数据或交互式的环境),以及可用于训练的计算量。算法创新和数据很难追踪,但计算量是可量化的,这为衡量人工智能的进展速度提供了机会。当然,大规模计算的使用有时候会暴露当前算法的缺点。但至少在当前的许多领域中,更多的计算似乎就可以预见更好的性能,并且计算力常常与算法的进步相辅相成。
对于“计算能力”,我们知道著名的“摩尔定律”(Moore's law):集成电路上可容纳的元器件的数目,约每隔 18-24 个月便会增加一倍,性能也将提升一倍。
今天,非盈利的AI研究机构OpenAI发布了一份“AI与计算”的分析报告,报告显示:
自2012年以来,在最大的AI训练运行中所使用的计算力呈指数增长,每3.5个月增长一倍(相比之下,摩尔定律的翻倍时间是18个月)。
自2012年以来,这个指标已经增长了30万倍以上(如果增长一倍的时间需要18个月,仅能增长12倍)。

计算能力的提升一直是AI进步的一个关键要素,所以只要这种趋势继续下去,就值得我们为远远超出当今能力的AI系统的影响做好准备。
AI计算的“摩尔定律”:3.43个月增长一倍
对于这个分析,我们认为相关的数字不是单个GPU的速度,也不是最大的数据中心的容量,而是用于训练单个模型的计算量——这是与最好的模型有多么强大最为相关的数字。
由于并行性(硬件和算法)限制了模型的大小和它能得到有效训练的程度,每个模型的计算量与计算总量的差别很大。当然,少量的计算下仍取得了许多重要的突破,但这个分析仅涵盖计算能力。
Log Scale
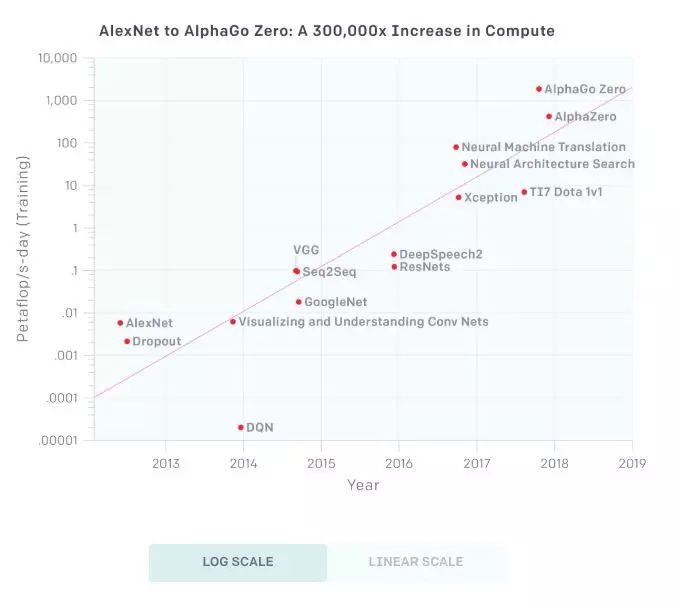
上面的图表显示了用来训练一些著名模型并得到较好结果的计算总量,单位是petaflop/s-days,使用了大量时间计算,并提供了足够的信息来估计所使用的计算。1 petaflop/s-days(pfs-day)是指一天执行每秒10的15次方次神经网络操作,或总计10的20次方次操作。这个compute-time的单位是为了方便,类似于能量量度单位千瓦·时(kW-hr)。
我们没有测量硬件的峰值理论FLOPS,而是尝试估计执行的实际操作的数量。我们将加法和乘法作为单独的操作,将任何相加或相乘计算为一个操作,而不考虑数值的精度(因此“FLOP”不太适当),并且我们忽略了集成模型。在本文附录中提供了该图表的示例计算。

Linear Scale
结果显示,最优拟合线的翻倍时间(doubling time)是3.43个月。
这一趋势每年以10倍的速度增长。部分原因是由于定制硬件,允许在一定的价格下(GPU和TPU)每秒执行更多的操作。但更主要的因素是研究人员不断地寻找新的方法来并行地使用更多的芯片,并愿意支付更大的成本。
4个时代
从上面的图表,我们可以大致划分为4个时代:
-
2012年之前:为机器学习使用GPU并不常见,因此图表中的任何结果都很难实现。
-
2012年至2014年:在多个GPU上训练的架构并不常见,因此大多数结果使用1-8个GPU,性能是1-2 TFLOPS,总计为0.001-0.1 pfs-days。
-
2014年至2016年:大规模使用10-100个GPU,性能为5-10 TFLOPS,结果为0.1-10 pfs-days。数据并行性的收益递减意味着更大规模的训练运行的价值是有限。
-
2016年到2017年:允许更大的算法并行性的方法,例如大的batch size、架构搜索和专家迭代(expert iteration),以及TPU等专用硬件,更快的互连等,大大增加了这些限制,至少对某些应用程序来说是如此。
AlphaGoZero / AlphaZero是大规模算法并行性最显著的一个示例,但现在其他许多这样大规模的应用程序在算法上已经是可行的,并且可能已经在生产环境中应用。
这种趋势将持续下去,我们必须走在它前面
我们有很多理由认为图表里显示的趋势可以继续下去。许多硬件初创公司都在开发AI专用的芯片,有些公司宣称他们在未来1-2年内将能够大幅提高FLOPS / Watt(这与经济成本紧密相关)。通过简单地重新配置硬件以降低经济成本,也可以完成相同数量的操作。在并行性方面,以上描述的许多最近的算法创新原则上都可以结合在一起——例如,架构搜索算法和大规模并行的SGD。
另一方面,成本最终将限制这个趋势的平行度,物理学也将限制芯片的效率。我们认为,目前最大规模的训练运行采用的硬件成本仅为数百万美元(尽管摊销成本要低得多)。但目前大多数神经网络计算仍然用于推理(部署),而不是训练,这意味着公司可以重新调整用途或购买更多的芯片进行训练。因此,如果存在足够的经济刺激,我们可以看到更多的大规模并行训练,从而使这一趋势持续数年。全世界的硬件总预算每年达1万亿美元,因此绝对的限制依然很远。总的来说,考虑到上述数据、计算指数趋势的先例、机器学习特定硬件的研究以及经济激励,我们相信这种趋势将持续下去。
对于这种趋势将持续多久,以及持续下去会发生什么,用过去的趋势来预测是不足够的。但是,即使计算能力迅速增长的潜力处于合理范围,也意味着今天就开始解决AI的安全问题和恶意使用问题是至关重要的。远见对于负责任的政策制定和负责任的技术发展都至关重要,我们必须走在这些趋势前面,而不是对趋势反应迟钝。
方法和最新结果
两种方法用于生成这些数据点。当我们有足够的信息时,我们直接在每个训练样例中描述的架构中计算FLOP的数量(相加和相乘),并乘以训练期间的前向和后向通道总数。当我们没有足够的信息来直接计算FLOP时,我们查看了GPU的训练时间和使用的GPU总数,并假设了使用效率(通常为0.33)。对于大多数论文,我们能够使用第一种方法,但对于少数论文,我们依赖第二种方法,并且为了进行一致性检测,我们尽可能计算这两个指标作为。 在大多数情况下,我们也向作者证实了这一点。计算并不是精确的,但我们的目标是在2-3倍的范围内做到正确。我们在下面提供一些示例计算。
案例1:计数模型中的操作
当作者给出正向传递使用的操作数时,这种方法特别容易使用,就像在Resnet论文中(特别是Resnet-151模型)一样:

这些操作也可以在一些深度学习框架中以编程方式计算已知的模型体系结构,或者我们可以简单地手动计算操作。如果一篇论文提供了足够的信息来进行计算,它将会非常准确,但在某些情况下,论文不包含所有必要的信息,作者也无法公开它。
方法2的示例:GPU时间
如果我们不能直接计算,我们可以看看有多少GPU经过多长时间的训练,并且在GPU利用率上使用合理的猜测来尝试估计执行的操作次数。我们强调,这里我们不计算峰值理论FLOPS,但是使用理论FLOPS的假定分数来尝试猜测实际FLOPS。 根据我们自己的经验,我们通常假设GPU的利用率为33%,CPU的利用率为17%,除非我们有更具体的信息(例如我们有和作者进行交流或在OpenAI上完成这些工作)。
举个例子,在AlexNet的论文中提到“在两个GTX 580 3 GB的GPU上,训练我们的网络需要5到6天的时间”。在我们的假设下,这意味着总计算:

这种方法近似度更高,可以很容易地减少2倍或以上,我们的目标仅仅是估计数量级。在实践中,当这两种方法都可用时,它们通常会很好地排列(对于AlexNet来说,我们也可以直接计算操作,在GPU时间方法上,计算结果分别是 0.0054 pfs-days和0.0058 pfs-days。

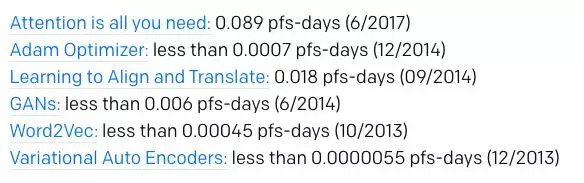
使用适量计算的最新结果
大规模计算当然不是产生重要结果的要求。最近许多值得注意的结果仅使用适量的计算。 以下是使用适度计算的结果的一些例子,它提供了足够的信息来估计它们的计算。我们没有使用多种方法来估计这些模型的计算结果,对于上限,我们对任何缺失的信息进行了保守估计,因此它们具有更大的整体不确定性。这些估计对我们的定量分析并不是十分重要,但我们仍然认为它们很有趣,值得分享: