

作者:二八
人工智能已经酝酿数十年,而今已在各个领域开花结果,比如自动驾驶、人脸识别、医疗等领域。
而在信贷审批领域,如果没有人工智能技术,将无法大规模的发展。
下面的分享,是一本财经学院主办的“三天两夜CRO闭门训练营”中,快牛金科CTO胡亮分享的节选:人工智能的发展逻辑,以及在信审中的应用。
01 人工智能的应用
每隔半年一年,就会有一些新的科技冒出来。比如随着AlphaGo的出现,人工智能技术进入了公众视野。
AlphaGo战胜了李世石, AlphaGo master战胜了柯洁。但事实上,Master之后,又一个版本AlphaGo zero,以89:11的比分,战胜了Master。
人工智能在围棋领域实在没有探索的必要了。所以,此领域人士希望把AI的技术能力应用在其它更有意义的领域中去,比如智能医疗、健康中。
其实,人工智能现在已经应用在了很多地方,比如自动驾驶。其中一大玩家Google已经利用Google街景、地图的数据,做这方面的尝试。而特斯拉是目前在使用上面比较成熟的一家。前不久百度也宣布,要在今年7月量产无人驾驶。
而在很多金融产品中,也都有人脸识别和远程开户的功能。还有刷脸登录,运用比较早的是支付宝的刷脸登录,以及苹果的iPhoneX,成功率和安全性非常高。
还有智能安防。在高铁、飞机场等人群集中的地方,可以实时捕捉视频里人脸的信息。这些信息和公安部或相关机构后台数据做比对后,用于反恐识别、逃犯追踪都很有效,能形成强大的天网。
除此之外,还有很多如客户、翻译、同声传译等领域的智能化改造。而这背后,本质上都是由于人工智能的技术成熟。
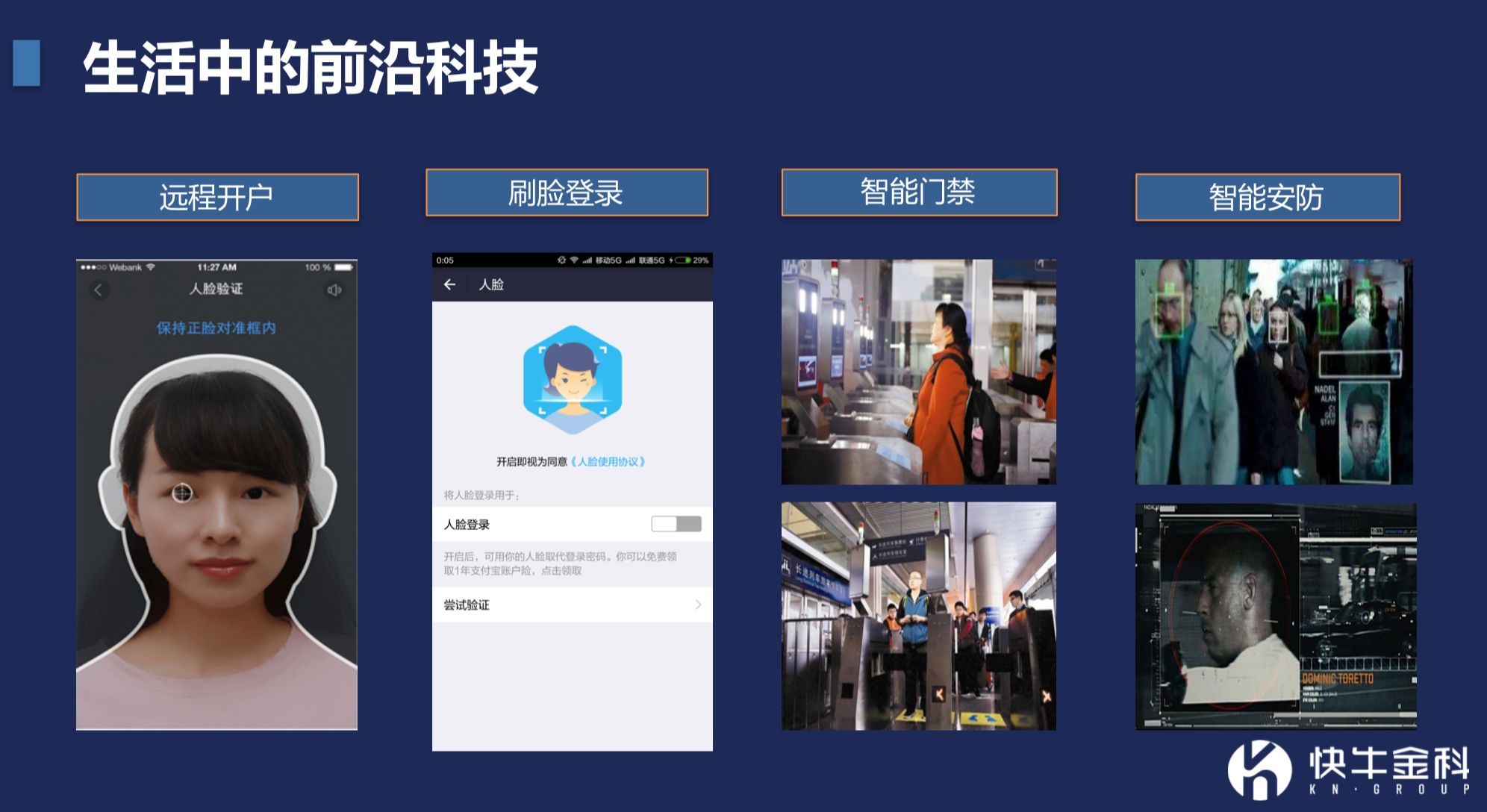
想要了解人工智能,要追溯到人工智能行业的发展中。
02 人工智能的发展史
它起源是在1956年。美国一个叫麦卡锡的学者,召集了一帮在数学和计算机领域的牛人,比如信息论创始人克劳德·香农、现在被誉为人工智能之父的马文·闵斯基。他们开了两个月的会,试图总结出来,什么是人工智能?
那时,距离第一台计算机的发明,只有十几年的时间。人们想弄清楚,计算机能否像人一样智能。
其中希尔伯特的《23个问题》中的一个问题,对此产生了巨大的启示意义。他问,是不是世界上所有的事情、命题、理论都可以写成数学公式?
之后,这成了人工智能尝试的第一个方向。人们试图去建立一套符号体系,把生活中所有的问题都试图用符号体系来进行数据运算。当然这是不太可能的,这套符号体系,发展得越来越复杂,越来越难以理解。
当时,有人觉得只有逻辑不行,还要有知识。所以在七八十年代,又兴起一个新的高潮——建一个专家系统,试图把人们所掌握的知识都装到计算机中,让计算机拥有部分人工智能。
但这系统存在一个致命的问题,就是它不能主动学习。而新知识产生非常快,人工不可能把所有知识灌进去。所以当时又有了一个想法——让机器自主学习。
1986年,反向传播算法的提出让大规模多层神经网络的训练成为可能。一个里程碑事件,就是1997年IBM的深蓝,第一次在国际象棋领域战胜了人类。2012年,ImageNet图像识别竞赛,深度卷积神经网络算法的使用,使得图片识别错误率大大降低,人工智能在“看特定的图”这件事上第一次接近了人类。到了2016年,AI已是每个人都耳熟能详的概念。

03 AI在信审中的应用
机器学习,是人工智能发挥的关键。
如何用机器学习来做信审贷款呢?流程分为四个步骤。
1、把实际问题抽象为数学问题。
要做一个信贷审批的机器学习模型,首先就要理解实际问题,拿到一批比如年龄、性别、所在地域,收入情况等用户数据,抽象为数学问题。
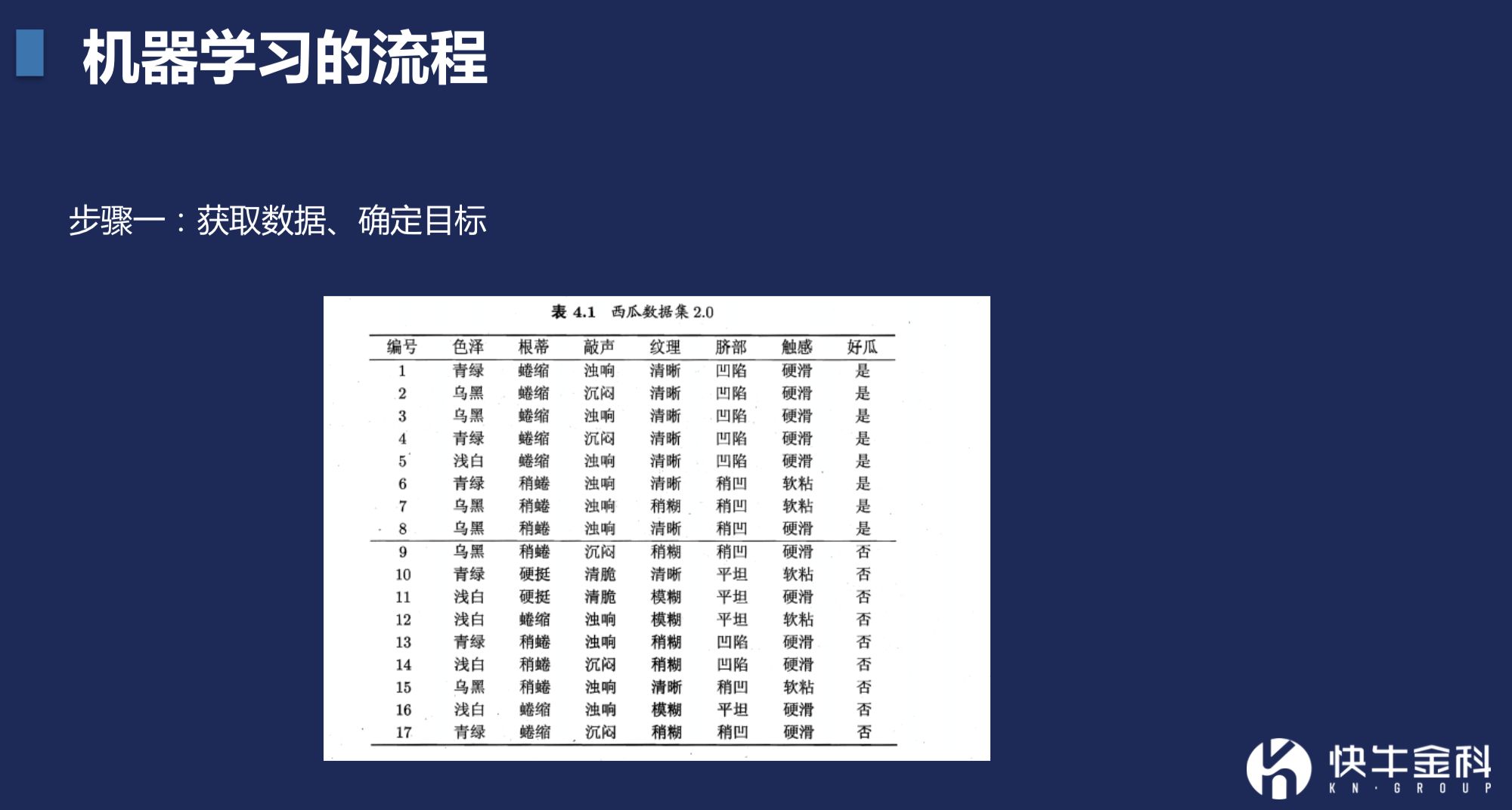
这就如在市场挑西瓜一样。我们希望买一个甜的,怎么挑呢?无非是看皮,是绿色还是偏白,或者是听声音是否清脆,或者看瓜蒂是否新鲜。根据这些子决策,形成结论。而如果用数据或者学术的方式来看,就可将上述全部数据化。
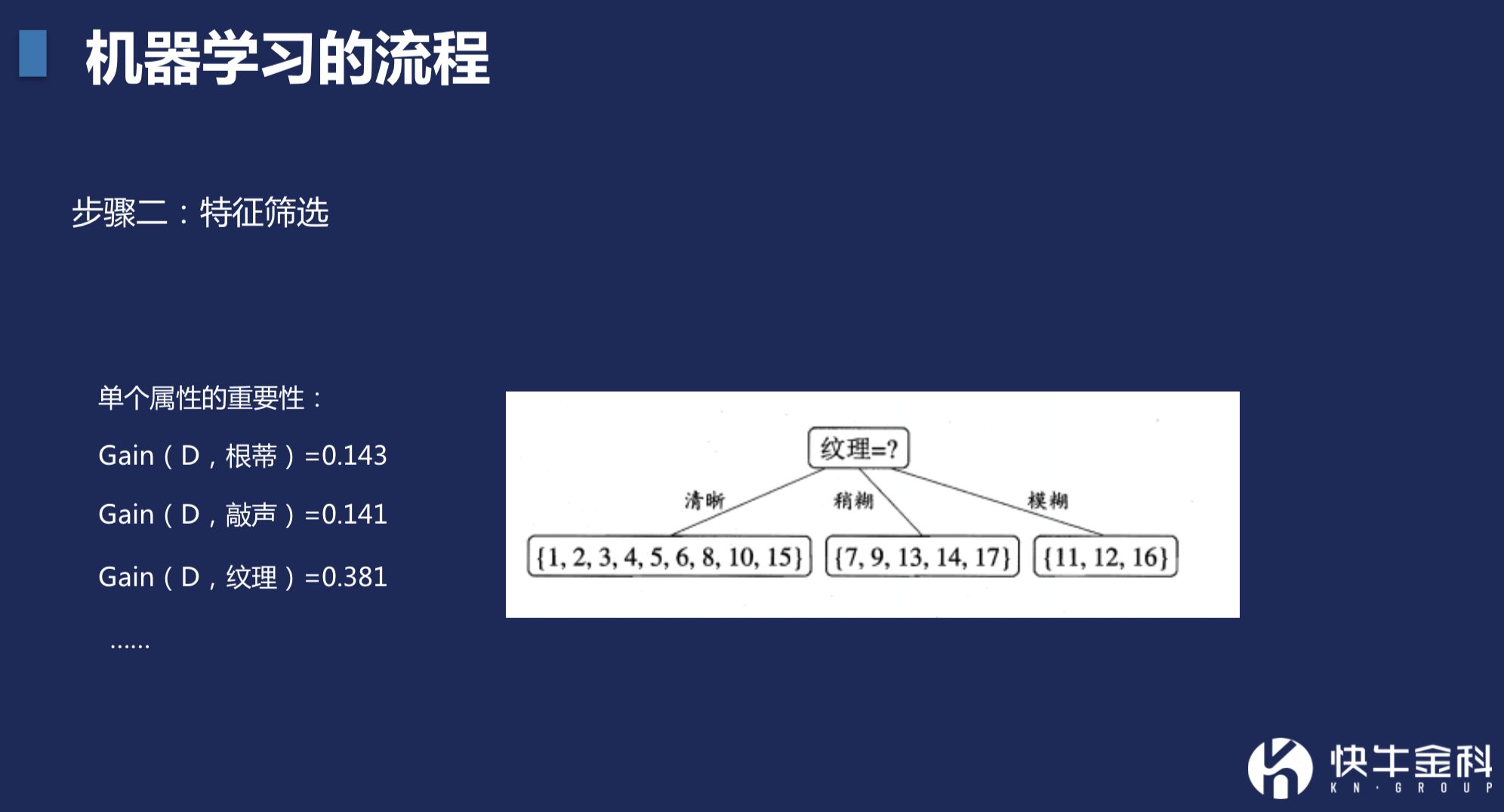
第二步,做特征筛选,比如纹理有3种情况,清晰、模糊、不模糊。按照是好瓜的概率,越清晰是好瓜的概率越高。纹理对于是否是好瓜有预测性,那这个数据就有价值。除了纹理,再加上根蒂、触感等有价值的数据,就可以做出一个数学模型。
第三步,以什么样的途径去筛选好瓜的概率最大呢?就要训练,最终训练出一个最好的途径。
比如你发现某用户是某些敏感地区的人群,就可能直接拒绝,因为这个地区坏人概率很高。如果是非敏感地区人群,就分多种情况。比如是公务员,涉及一系列决策;如果不是公务员,又是一系列决策。
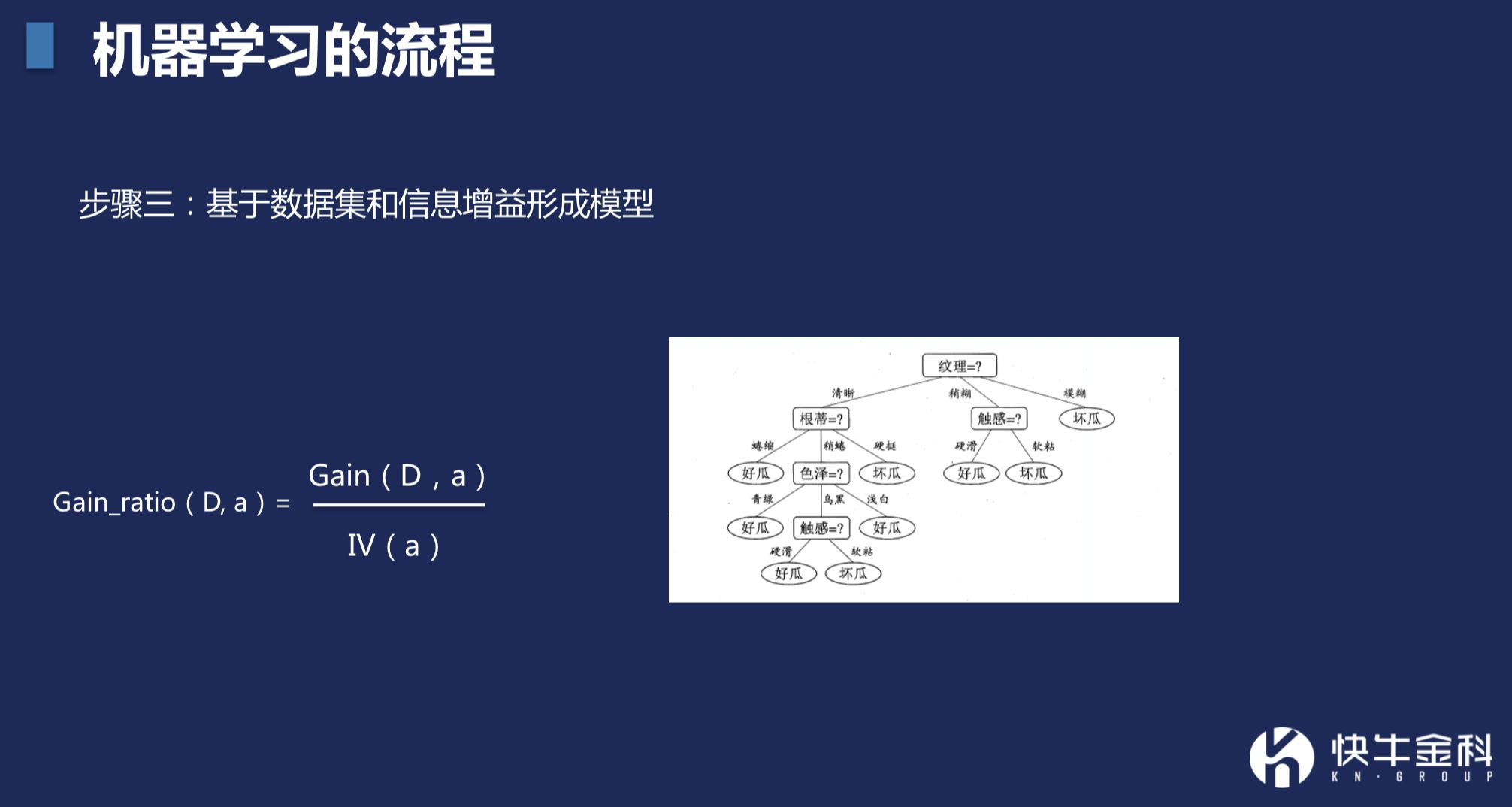
根据这样一棵树,一个用户进来,可以最终给到是否审批的结论,这就形成一个模型。这棵树在实际应用中,会复杂很多,分支会非常多。不可能手工列出一个模型出来,这就需要依靠机器学习的方式把模型学习出来。
第四步,学习出来之后,就要去评估这个模型的好坏,这就是测试。
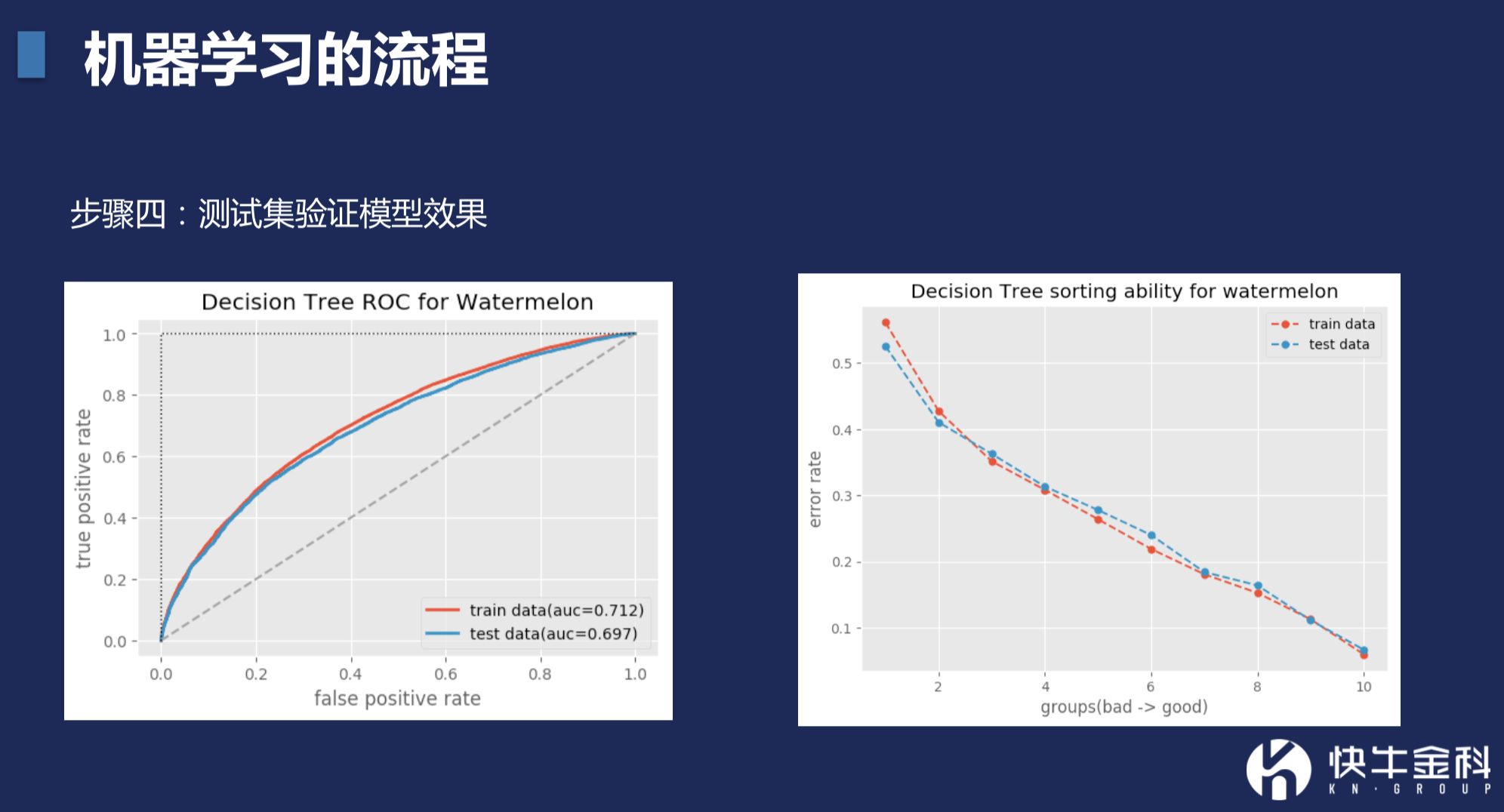
判断的方法,有几个常见的方式。第一个是ROC曲线,底部横坐标是把坏人放进来的概率。在0.2时,意味着放进来20%的坏人。中间虚线指的是乱猜的。如果模型很靠近这条线,意味着模型跟瞎猜没啥区别。如果模型越靠上、左,或者覆盖的面积越大,模型效果越好。
其中红线、蓝线,红线是训练集上的效果,蓝线是测试集上的效果。好的模型应该是红蓝线很近,甚至重叠。如果差异很大,只是理论上很好,在实践中,会打折扣。
第二种模型是排序能力的判断。
所谓的排序能力,就是知道好坏的程度,比如根据模型得出A和B都可以给放款,那么谁更好?C和D都不能放款,那么哪个更差?
更直观的例子就像芝麻分,从350到950的一个区间,对吧?那么芝麻分它好像是坏呢?很重要一点是要考虑它的排序能力。950的人一定要比750的人好,750的人一定要比700的人要好。如果750分的人放到贷款的位置比800分的人还要更优秀还更低,那它的排序性就不行。
这个应用就是风险决策时,风控策略是收紧,还是放松。如果没有排序能力,就没办法做这个判断。如果有排序能力,要收严,只给分高一点的收就可以了。排序能力,是信贷审批模型中,非常重要的衡量指标。
