
概率是度量一件事发生的可能性,它是介于0到1之间的数值。
我们抛一枚硬币,它有正面朝上和反面朝上两种结果,通常用样本空间S表示,S={正面,反面}。
如果把硬币抛两次呢?它拥有四种结果,S={(正面,正面),(反面,反面),(正面,反面),(反面,正面)}。抛三次则是八种。
现实中的概率事件更复杂,比如六合彩,它会有多少种可能性?这时不能再像硬币一样心算了,要用到组合的知识。
组合和排列
组合是高中课本的内容,当需要从N个物体中选取n个物体,可以通过组合公式计算出可能的结果数量。

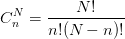
公式或许和大家印象中的有差异,因为中国国内的数学教材以苏联为主,N和n的上下位置与欧美教材是相反的。我这里以欧美规范为主。
从五个颜色各异的小球中随机抽取两个时,将数值带入到公式,得出答案为10种。
排列是组合的特殊情况,当要考虑选取的顺序时,相同的n个物体,因为不同的顺序会有不同的结果,公式变为:
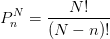
依旧是五种颜色的小球,这时需要考虑选取的小球颜色先后次序,代入求出答案变为20种。
在Excel的函数中,COMBIN和PERMUT函数分别对应组合和排列。
事件及概率
前面我们已经定义了样本空间S,称事件为样本空间的一个子集,它是概率论的基础。
硬币正面朝上是一个事件,反面朝上也是一个事件。当硬币扔两次时,也可以定义一个事件叫至少有一次正面朝上,此时事件为{(正面,正面),(正面,反面),(反面,正面)}。
单纯的事件没有意义,要结合概率来思考。比如至少有一次正面朝上,它由(正面,正面),(正面,反面),(反面,正面)三个事件求和得出,概率为75%。
通常,如果能确定一个试验的所有样本点并且能够知晓每个样本点的概率,那么我们就能求出事件的概率。
虽然大量的样本点会造成计算的繁琐,但是通过一些基本公式和定理能快速计算。
事件A的补指所有不属于事件A的样本点组成的事件。概率中有一个可视化技巧叫文氏图/维恩图。
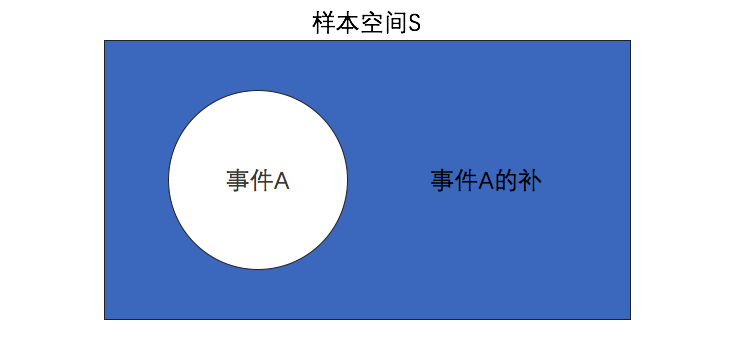
事件的补可以定义为P(A-),有P(A-)+P(A)=1。针对抛两次硬币至少有一次朝上的概率为75%,它的补集为一次朝上都没有,其概率为1-75%=25%。
概率的公式
事件的组合有两个概念:并和交。事件A和B的并,可以用SQL中的Full join理解,即包含了事件A和事件B的所有样本点。记作A∪B。
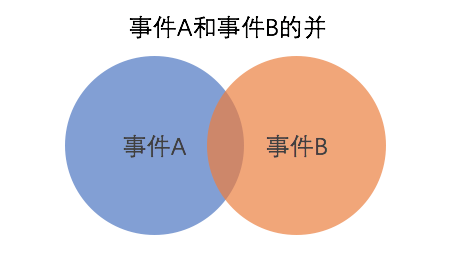
两个圆形区域所在的部分就是事件A和B的并,其中重叠的部分说明有一些样本点即属于A又属于B,它可以称之为交,可以用SQL中的Inner Join理解。记作A∩B。
通过交和并,引申出概率中的加法公式:
P(A∪B) = P(A)+P(B) - P(A∩B)。P(A∪B) 是两个圆形面积,P(A)是蓝色圆面积,P(B)是橙色圆面积,当两者相加时,会多出一块重叠区域,于是减去P(A∩B)进行修正,得出正确的结果。
再来考虑事件中的一种特殊情况,互斥事件。事件A和事件B中,当一个发生另外一个肯定不发生,则称为互斥事件。此时,P(A∪B) = P(A)+P(B) 。
生活中很多概率处处相互关联和影响。某个事件A发生的可能性受到另外一个事件B的影响,此时A发生的可能性叫做条件概率,记作P(A|B)。表明我们是在B条件已经发生的条件下考虑A发生的可能性,统计学中称为给定条件B下事件A的概率。
对于任何条件概率,存在:
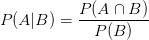
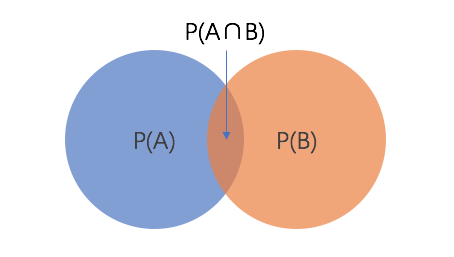
这个公式依旧可以用文氏图解释。橙色圆表示事件B已经发生,如果想要知道B已经发生的情况下事件A发生的概率,则只能考虑橙色圆和蓝色元的交集部分即P(A∩B)。此时P(A∩B) 除以P(B)即给定条件B下事件A发生的概率。
当某一事件受另外事件的影响,我们称其为条件概率。相反,某一事件完全不受另外事件的影响则为独立事件。如果事件A和事件B相互独立,则P(A|B)=P(A)。
互斥事件和独立事件不是一回事,独立事件是完全不相关的情况,而互斥是某一事件发生另外一个事件必然不发生,它们是相关的。
贝叶斯公式
条件概率既然是通过一个事件发生了来计算另外一件事发生的可能性,那么如何计算呢?不妨先看一个经典案例。
如果某种疾病的发病率为千分之一。现在有一种试纸,它在患者得病的情况下,有99%的准确率判断患者得病,在患者没有得病的情况下,有5%的可能误判患者得病。现在试纸说一个患者得了病,那么患者真的得病的概率是多少?
在下意识的判断中,我们可能认为是50%左右的数据,或者更高。然而实际并不是。
将求解策略转换为树形图的方式。按照患病率为千分之一,将人群划分成健康人群和患者,分别是99900个和100个。然后再根据试纸对不同人群的概率求解。
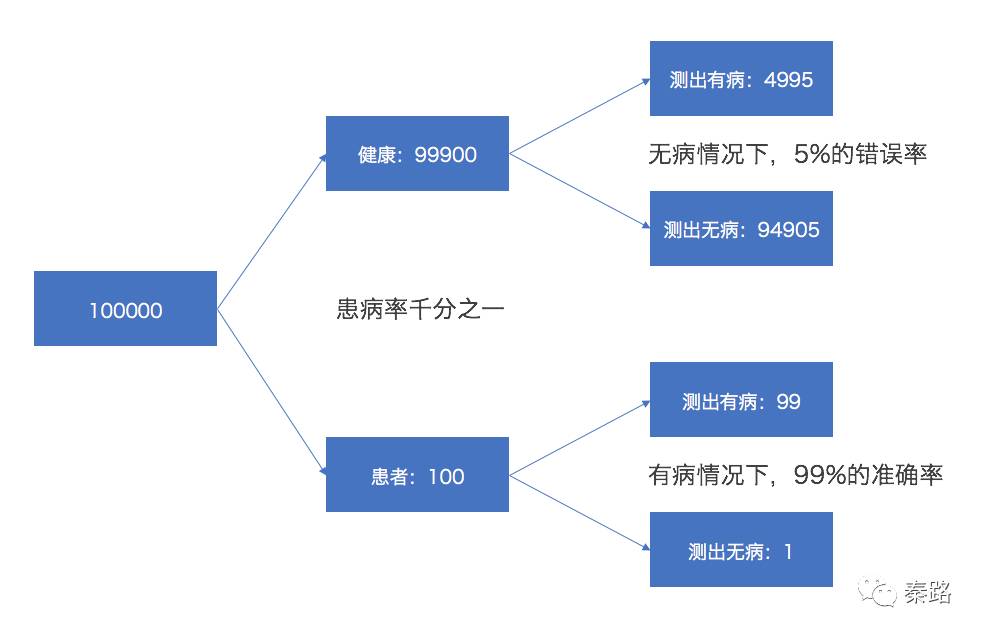
最终健康人群中误测出有病的是4995个,而真正患者中测出来是99个。所以当遇到一个患者被测出来有病,实际上真正得病的概率是99/(4995+99)=1.9%。
这个概率非常低,试纸绝大部分的判断都是误诊,它产生的原因在于患病率千分之一这个前提条件。在统计学中把它称为先验概率,即事件发生的因,根据先验概率的变化,得到所谓的后验概率,即事件发生的果,贝叶斯定理就是其中的一种计算方法。数据推导过程大家有兴趣可以自行查阅,都是基础上文公式的简单应用
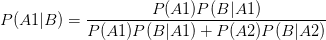
P(A1)代表是真实患者的概率,P(A2)代表是健康人群的概率,P(B)代表试纸查出患者的概率。于是得出:
P(B|A1)为真实患者条件下试纸查出患者的概率,即99%。
P(B|A2)为健康人群条件下试纸误判为患者的概率,即5%。
P(A1)为真实患病率千分之一,P(A2)为健康率千分之九九九。
P(A1|B)是在B发生的情况下A发生的可能性。应用在上文的例子中,就是试纸查出其为患者的情况下,他是真的患者的概率。将数字都代入公式计算。
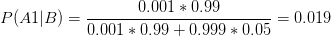
和我们用树形图计算出的答案一样。不妨思考一下,如果试纸获得了改进,对真实患者的判断准确率优化到99.9%,对健康人群的误判率降低到0.1%。此时P(A1|B)为多少?其实还是不到50%,大家有兴趣可以计算一下。
上文列举的公式是两事件模型,当先验概率A是多个时,正式表达为:
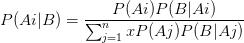
贝叶斯在Excel中并没有简化的函数,需要手动处理,新手可能对概念还是有些模糊,多做几次练习就好了。可以借助树形图辅助判断。
再来做一道练习题:中国五百位富豪,其中,读过大学的只有30%,是否能说明读书无用论?
并不能,因为它涉及了一个先验概率即所有中国人中读大学的比例,更准确地说,是富豪们读大学年代的读大学比例。不妨大家自己查阅资料作出解答。
上文谈及的都是理论,数据的应用场景呢?比如拼写检查,我输入了一个字典中没有的英文单词:thi,这时候机器就要猜测是the,还是this?这个问题就转换成概率中的P(机器猜测的单词 | thi ),当单词为thi时,机器所猜测的单词准确率是多少?
应用贝叶斯公式转换:P( this | thi ) = P( this )P( thi | this ),以及P( the | thi ) = P( the )P( thi | the )。因为分母是样本空间常数所以可以略去,P( this )代表的是this这个单词在全体文本中出现的概率,P( thi | this )代表的是this这个单词打错为thi的概率,结果为这两个概率的乘积,以此类推。
P输出的都是概率,假设计算后the的概率为80%,this的概率为75%,此时输入法纠正就把the排在第一,this排在第二。
贝叶斯定理在数据分析中是一种常用的手段,除了对日常生活中违背经验主义的各种数据陷阱,它也能广泛应用在机器学习诸如邮件识别、文本分词、拼写检查等场景中。
