


文 | 娱乐资本论 James
上周,ChatGPT正在测试一个独立于其大模型对话框之外的AI搜索功能,将使用专属网址 search.chatgpt.com ,据说支持以图搜图,还可能包括天气、计算器等小工具。
作为AI领头羊,OpenAI的几乎每一个行动都能激发业界的热烈讨论。不过北京时间周二凌晨的发布会上没有公布和搜索相关的信息,这次开放的GPT-4o模型主要增强了语音、图像方面的多模态能力。
有多样的证据显示ChatGPT搜索确实在做,还有人号称刷到了灰度测试资格。与此同时,在AI搜索这条战线上,国外有Perplexity,国内有天工、秘塔;“传统”搜索引擎如谷歌、必应、百度、360也纷纷入场。视智未来发现,不管公司是否正在开发基础大模型,要推出一个AI搜索界面并不困难,甚至最短只需要一位个人开发者忙碌3天。
不过,秘塔科技的COO王益为对视智未来表示,想入场做搜索也没有那么容易。做AI搜索的技术力和产品力都同样重要,也必须想清楚市场定位、商业化和覆盖算力成本的问题。
“我有个理论,一个工具的合理定价,大约是它所替代的工作价值的1/10。”王益为说,“秘塔AI搜索现在产品大概是80分水平。如果要达到90分或更高,就是说用户有强烈的付费意愿。”

多模态“抢镜”已久,单纯的语言模型似乎有点寂寞,而AI搜索似乎重新点燃了这方面的热情。它会是继视频和音乐创作之后的下一个AIGC热点领域吗?是不是很快就会进入激烈的“千搜大战”了?
VOL.1 AI搜索,怎么这么像是大模型
在ChatGPT的搜索功能正式亮相之前,外界充满了传闻和猜测。X(Twitter)用户 @btibor91 根据泄露的部分前端代码,绘制了ChatGPT搜索界面的假想效果图:

然而,我们可能很难看出新的搜索界面与之前传统的GPT聊天框之间有什么区别。
与此同时,自媒体“赛博禅心”刷到了灰度测试中的 ChatGPT搜索,下面是他尝试搜索的结果页面:

这是视智未来使用ChatGPT Plus早就有的联网功能,输入的提示词以及获得的结果页面:

——不能说非常相似,就是一模一样嘛!
如果你感觉AI搜索跟能联网的ChatGPT没啥本质区别,你的感觉是对的。目前结合AI大模型与搜索的方式,其背后的核心原理都是RAG(检索增强生成,Retrieval-Augmented Generation)。
2020年,初创公司Cohere的帕特里克·刘易斯(Patrick Lewis)在一篇论文中发明了这个术语,他因为缩写“不太讨人喜欢”而道歉,“早知道我们的工作会变得如此出名,我们肯定会好好想一个更好听的名字。”
简单来说,RAG就是将输入的提示词转换为搜索关键字,根据网上搜索到的页面内容进行阅读理解,然后限定大模型需要基于这些内容生成答案,而不是依赖模型自身的知识库。
市面上的大模型聊天产品,除了ChatGPT等少数,大多数模型都将联网搜索功能免费提供,像文心一言甚至不支持取消联网功能。
这实际上已经就是一种形式的“AI搜索”了。此时,调用大模型API生成的结果,跟在大模型官网对话的结果,就会产生一定的差异。
除了上面的ChatGPT和搜索结果对比,视智未来还对比了文心一言的输出和百度“简单搜索”App的AI搜索结果,以及谷歌Gemini的输出和谷歌搜索增强的结论。
结果是,同一厂家的大模型联网结果和AI搜索结果,很大程度上是可以相互替代的,尽管每次生成的结果都不完全相同。

王益为觉得RAG就是最大限度减少幻觉的最优解。他认为,让大模型基于自己训练的知识库回答问题类似于闭卷考试,而使用搜索引擎则相当于开卷考试,将准确率大大提升。
秘塔的拳头产品“写作猫”还开辟了基于搜索的“事实验证”功能,在一篇生成的或人类写作的文章中,挑出可能有事实错误的地方,并提供网上相关信息的链接。
当然,因为也不能100%依赖AI的判断,这个功能将报警阈值调得比较低,有时会有误报,但“宁可杀错,不可放过”,主要是方便作者人工二次检查。然而,针对RAG也存在不少质疑的声音。例如,尽管RAG能够提供更有用的参考资料,但生成内容的逻辑仍是一个黑箱,因此可控性并不强。有时候,即使指定了必须依据的材料,模型仍可能会“任性”地给出与材料不相关的答案。另外,特别是在涉及推理能力的搜索任务中,模型本身的局限性可能无法仅通过引入高质量的材料得到解决。例如,当要求直接提供网上文章能摘抄的具体段落时,模型可能能够处理;但如果需要对搜到的历年数据进行筛选、求平均值或极值等结构化操作时,出错的概率依然很高。
既然是用了搜索增强,那么搜索结果是哪里来的呢?
有的团队会像自己做大模型一样,连搜索爬虫也是自己做。比如视智未来此前采访昆仑万维的董事长兼CEO方汉,他就解释说,昆仑万维的团队从海外产品Opera News起算,在搜索领域有6-7年的经验积累。天工AI搜索对重点网站的抓取频率已经提升到每分钟一次。
方汉还提到,昆仑万维积累了丰富的预训练数据收集、清洗、深度加工等能力。他们也在研究如何确保信息的真实性,比如对各种信息源网站进行打分;以及如何调整内容以适应国内用户、如何避免信息茧房等问题。但可能更简单的方法,就是套用现成的搜索引擎。ChatGPT不用问,用的是必应搜索。而根据The Information等报道,想做“谷歌杀手”的Perplexity 其实使用自动化系统来访问来自必应和谷歌的数据。它采用必应的 API 对结果中的信号进行排名,以确定网页的相关性、质量和权威性。
在Perplexity们的界面当中都可以指定限定来源搜索,而要想做到这一点,最简单的方式就是用一个site语法来实现;用提示词也是一样的。
秘塔科技的王益为告诉视智未来,在写作猫当中可以引用学术文献作为文章内容的来源说明,这有助于AI帮学生们自动生成一篇论文的底稿。不过截至目前,学术搜索依然是检索一些公开的资源,比如知网的网页版等等。系统只能抓取标题和摘要等公网能访问的信息,暂时还不能访问正文等需要付费的内容。
秘塔AI搜索也有一个专门的学术搜索分区,其检索范围和写作猫的学术文献检索是一样的。因此,如果真的有人想“量产”论文,一定要记得亲自做好事实核查工作。其实,AI产品缺内容的问题,不管是在训练大模型的时候,还是在用大模型去搜索的时候,同样都是不能绕开的,如果要强行输出它原本访问不了的内容,那就会出现幻觉和编造了。
在国内外,都有众多优质的信息来源是不开放对外搜索的,例如购物网站,抖音、小红书等社交网络,都是禁止搜索引擎爬虫。还有一些社区的法务部门,会在检测到你使用了他们的信息之后开始行动。
所以,这些问题既不能在搜索引擎层面来解决,也不能用训练大模型来解决,那么将“搜索引擎+大模型”结合在一起,肯定也不要指望它能解决。在“围墙花园”之外,也是巧妇难为无米之炊。跟全网AI搜索相比,将收费的新闻产品站内搜索替换成大模型驱动,可以说有更高的性价比。这不仅可以改善搜索质量,也可以成为付费墙的另一个吸引人之处,提高读者的参与度和付费意愿。
在过去的几个月里,《福布斯》和《金融时报》推出了自己的对话式文章数据库搜索框。Snopes、《卫报》、《商业内幕》等出版商也在考虑使用生成式AI改进其站内搜索功能。有媒体站方表示,“网站搜索不是一个广泛使用的功能,这给了我们一个在低风险环境测试AI的机会。”
VOL.2 AI搜索,拿什么抓住用户
除了你很熟悉的大模型对话框,加入联网能力之外,还有其它不同的AI搜索界面形态百花齐放。究其本质,可以说是一样的原理,换了不同的皮肤。
现有搜索引擎巨头会选择在搜索结果的最顶部,插入一小段由AI生成的总结,可以参看上文展示的谷歌搜索的例子。
而早在文心一言上线之前,百度已经推出了名为“AI搜索智能增强”的能力,现在这一功能已经在越来越多的不同关键字的搜索结果页面上显示。
百度主打一个够用就行,倒也没完全追求一定要用大模型来生成。它始终没有将文心一言跟搜索结果页整合,而是停留在“简单搜索”等外围尝试。另一种展示方式是类似于微软必应集成的Copilot。在用户没有主动调用Copilot时,输入关键词的搜索结果将显示在页面的左侧,而Copilot生成的内容则显示在右侧。360搜索的展示方式与必应相同。
与之相比,并不是由“传统”搜索引擎做的AI搜索,则会使用一种重新设计过的,专门的三栏式AI搜索界面。这种设计的开创者是AI领域的“当红炸子鸡”Perplexity,这个名称在英语中意为“困惑”。
Perplexity的创始人Aravind Srinivas对自己公司开创的这种新型搜索界面非常敏感,他甚至在X(Twitter)上发文称Meta AI的首页设计模仿了他们,引发了一场小规模的争论。
在国内,采用这种界面的包括昆仑万维的天工和秘塔等。

风头正劲的Arc浏览器的iOS版本,对AI搜索采用了一种更简洁明了的“变体”界面,隐藏了其它竞品中一些可能干扰用户的可选项。
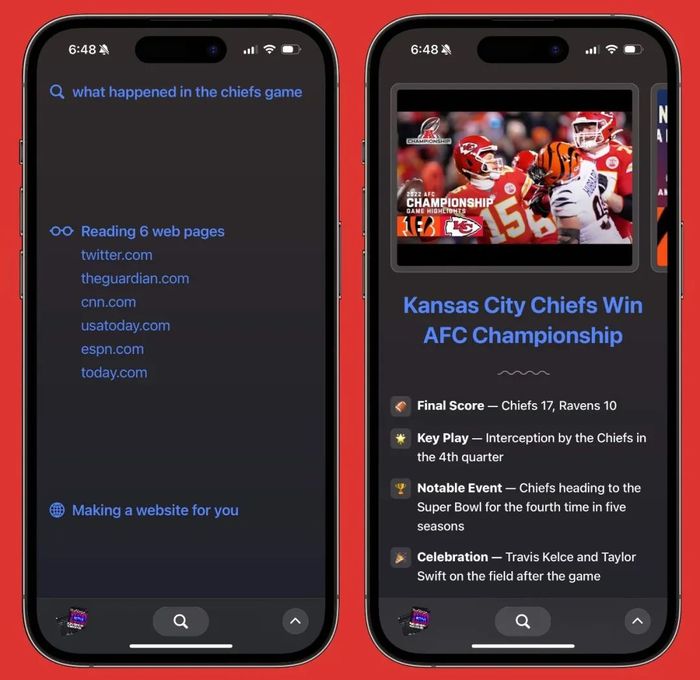
因为开源社区的帮助,做一个AI搜索的“开发成本”现在已经做到很低,甚至出现了可以同时选择搜索API和大模型API切换的开源界面方案,就是搜索引擎+大模型的“双重套壳”。
据说这款名叫ThinkAny的外壳由一位独立的开发者用了3天时间开发完毕。选择搜索范围、生成思维导图,切换大模型引擎,这些功能一个不落。
这样一看,AI搜索实际上是给大模型又套上了一层新的皮肤,找到了一个新的使用场景,也在解决人们对ChatGPT式聊天界面的“审美疲劳”。
如果这真的有用,那就像在去年年中来了一场“百模大战”一样,在接下来的一两个月,很有可能也会出现“千搜大战”的局面。
当ChatGPT最初引发轰动时,许多人都将对话框视为一种新形式的搜索,新的“互联网入口”。当时,视智未来还发布了一份关于如何生成有效提示词的《ChatGPT内容行业实用白皮书》,这些内容至今仍具有参考价值。实际上在“传统”搜索引擎时代,早有人困惑,为什么在搜索相同内容时,有些人能迅速找到答案,而其他人却一无所获?这可能涉及到所谓的“搜索引擎情商”。
当人们的输入从几个关键词扩展为更完整的提示词后,这个问题不但没有缓解,反而更严重了。人们不得不研究各种“咒语”或繁复的输入形式,甚至有专门的“提示词工程师”职位。大模型聊天产品的易用性对普通人来说,其实是下降的。
根据报道,谷歌正在研究新的工具,能让用户在查询时先经过一次提示词基础优化,然后再将优化后的提示词送给大模型,以期得到更优的答案,但效果尚待观察。人们通常不愿意从旧产品迁移到新产品。因此,习惯了传统搜索的用户,至少可以在原有的服务中无缝体验AI的新功能。相反,全新的服务可能会利用传统的搜索结果渠道来吸引用户。
视智未来注意到,字节跳动旗下的大模型聊天App“豆包”,通过在传统搜索引擎中大量推广,吸引了不少“神秘”的新用户。有的用户默默使用豆包,却不知道其他国内类似产品,如文心一言、通义千问、智谱清言或Kimi都没听说过。这一点非常奇怪。
实际上,豆包的策略是首先通过搜索引擎推广(SEO)战术,使用更精确的关键词吸引用户,然后将这些关键词通过豆包的回答,把引流链接贴到搜索结果页面。在推广抖音的时候,字节已经熟练运用了这种方法。
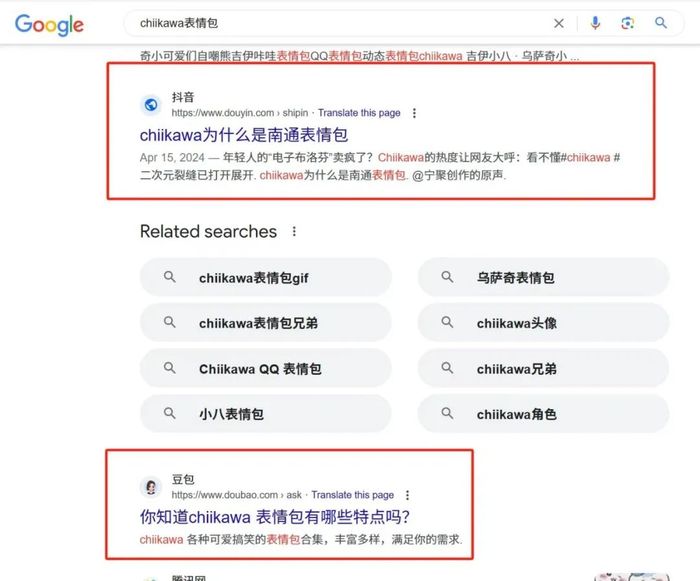
可以预见,如果有人通过某种方式,将自己的搜索请求从传统搜索引擎完全转移到豆包,并形成了新的习惯,这就意味着哪怕是本来不需要大模型的搜索请求,他们也是用AI搜索,因为他们更不愿意混搭使用多个不同的工具。
VOL.3 AI搜索,怎么才能不亏本
当所有人都涌入AI搜索赛道,是“学有余力”的大厂能赢,还是小但更专注的初创团队胜出?在不同的视角肯定有不同的答案,秘塔的COO王益为就从“小厂”角度出发,说了他自己的看法。
如何在其它家都做搜索的时候,体现差异化的竞争力?王益为说,“没有广告,直达结果”是秘塔AI搜索希望反复提及建立的用户心智。因为年轻人是写作猫产品最大的用户群,在产品刚一开始设计时,秘塔就决定放弃直接的广告形式。“没有广告,主要是考虑要吸引什么样的人。我们发布的第一条推广视频就是在也没有广告的B站发布的。”
对于百度和微软都提到过会研究“软性植入”结果中的付费广告位,王益为也态度谨慎,他说底线是推广结果不能影响答案的准确和公正。
“我认为一开始他们可能会选择简单粗暴的方式,就像谷歌那样直接在页面上展示广告。但随着时间的推移,可能会变得更加微妙,例如提供服务链接。你搜索‘家里漏水怎么办’,下面可能直接出现相关服务商的联系方式。但这需要考虑周全,你需要确保推荐的服务有一定程度的可靠性和背书,如果推荐的服务不靠谱,会直接影响到搜索引擎的声誉。这件事情的风险很大。”秘塔AI搜索的目的是直接给出用户需要的结果,而不是让用户在大量信息中筛选。王益为提到,“直达结果”是他们的目标。它的“研究”模式动辄一次生成3000字,在一大堆文本涌现出来的时候,确实令人印象深刻。
尽管这些字数很大程度上不能一字不改直接使用,但它一次给你3000字,你自己缩成五六百字能用的,也不失为一个解决之道。
在这方面,不同产品的表现差异,更主要体现在基底大模型的差异上。秘塔的多款产品共用一个自研大模型,王益为表示,因为他们的模型在语料方面积累更深,所以参数也不必一味求大,100亿(10B)对完成写作文章的任务优化来说已经足够。
秘塔AI搜索还能提供更深入的服务,比如转换成思维导图、以及“一键生成PPT”用于业务汇报。当然,也有其它家的产品提供将结果“一键生成信息图表”等类似的功能。放弃广告位,也意味着秘塔AI搜索对C端商业化的规划,仍将以会员订阅为主。
“从内部来看,我们会在产品达到一定质量标准时才发布。通常,如果有人愿意为此付费,就说明产品达到了我们自己认为的‘80分’水平,是真正有用的,而不仅是玩具。”
王益为表示,“秘塔AI搜索现在产品大概是80分水平。如果要达到90分或更高,用户有强烈的付费意愿,我们不排除将来收费,或者只对‘研究’模式收费。但我们还没有确定。”
收多少钱合适呢?文心的高级版一个月收费40元,360也在收费。“目前天工它们还没有收费,但它们有能力收。”
“我认为这是一个核心问题,你是否敢于收费?如果你不敢收费,就不能验证自己的产品是否有价值。无论你怎样夸大其词,最重要的是,是否有人愿意为之付费。如果有,那就很了不起。如果没有,就说明问题了。”写作猫仍是秘塔目前的主力业务,大约占了收入的80%。写作猫现在有大约1200万注册用户,付费用户大概只占3-4%。主要客户仍然是公务员和学校的个人用户。
此外,法律翻译服务仍在稳定地提供现金流。“今年刚开始销售的MetaLaw也表现不错,我认为今年能卖出几百万(元的销售额)是没有问题的。”
这种收入结构让王益为有点隐忧,因为通用大模型已经在改写、纠错等方面做得很好,
“我们提供的API服务,比如错别字检查、改写等,都比大模型的服务贵。不是因为他们能降成本,而是被GPT卷得价格非常低,实际上都是亏本的。而且使用我们API的人同样可以使用GPT。所以这部分简单任务的收入只要能保持稳定就不错了。”
对话中,王益为还向视智未来分享了另一个经验之谈。
“我有个理论,(在国内)一个工具的合理定价,大约是它所替代的工作价值的1/10。例如,MetaLaw的产品定价是499元/年。这个价格对许多律师来说是可接受的。否则,他们可能认为是有点用途,但是不值这个价。最开始我们尝试了一个1599元的价格,但一个都没卖出去。后来我们降到499元,付费意愿就上来了。”

秘塔因为创始人的背景因素,可以对法律AI创业轻车熟路,也见证了不少其它贸然进入法律AI的开发者碰壁。尽管如此,他们仍然深刻感受到追求盈利在国内的艰难。
“要知道,全国总共只有70万名律师。在这70万人中,可能只有10万人会使用AI产品。即使其中一半人购买了这个产品,按照我们现在的定价,也只是2500万的收入。要实现1亿的营收,就需要再找到3个类似的场景。”
如果今天正是“千模大战”的前夜,那么上面这些信息可以让我们窥探AI搜索的实际发展空间有多大。
AI搜索工具肯定会越来越多样和强大,但单纯的将大模型联网再改个形式,恐怕并没有真正理解搜索引擎的本质,也不理解用户如何使用搜索。
搜索引擎不仅仅是用来寻找信息的工具,更是一个多功能平台,能够直接回答问题,提供计算器、转换器等小工具,以及各种其他内置功能。目前的AI搜索虽然在某些方面比传统搜索更有优势,但它们的生成速度慢、结果呈现少、选择偏向不明确等问题,影响了结果准确性这一根本指标。
同时,改成搜索框后的用户体验也并没有产生本质上的飞跃。从这个意义上讲,OpenAI这次是用GPT-4o做语音助手,确实可能比推出搜索产品更有趣一些。
未来搜索引擎的发展,将更多取决于产品创新而非技术进步。要超越谷歌、百度、必应们,恐怕需要的不是先做一个联网的大模型再说,而是始终关注如何才能解决用户的实际问题。
