


界面新闻记者 |
界面新闻编辑 | 文姝琪 刘方远
“大模型”无疑仍是当下科技互联网界最大的热点。2022年末,OpenAI发布ChatGPT3.5,像一粒投入池塘的石子,迅速在国内人工智能赛道引发涟漪。
据中国科学技术信息研究所于今年5月发布的不完全统计数据,国内10亿参数规模以上的模型产品数已达79个,堪称“百模大战”。百度、腾讯、阿里、科大讯飞、商汤、百川智能等大厂或明星创业者带领的科技企业,纷纷跑步入场。
与“百模大战”一样让人眼花缭乱的是,针对大模型产品发布的评测榜单也层出不穷。理论上讲,能力相近的大模型在不同排行榜上的结果差距不该很大。但实际上,他们在不同榜单的排名结果可能是天壤之别。
8月15日,新华社研究院发布了《人工智能大模型体验报告2.0》,对国内主流大模型进行使用体验的横向测评。该榜单用500道题目评测了国内8款主流AI大模型,最终讯飞星火排名第一,百度文心一言排名第二,阿里通义千问排在倒数第二。
8月28日,SuperCLUE发布了中文大模型8月榜单,这是百模大战时代出镜率最高的榜单。总榜之上,GPT-4排名第一,百川智能的Baichuan-13B-Chat排在中文榜单首位。

9月,学术界当红开源评测榜单C-Eval最新一期排行榜中,云天励飞的大模型“云天书”排在第一,而GPT-4仅名列第十。
这三个榜单分别来自权威媒体、业界、学术界,已经是各自领域较为流行的榜单,结果差异尚且如此巨大,遑论其他。
据界面新闻记者了解,现在国内外各种叫得上名的大模型评测榜单不下50个,而他们的排名结果,鲜有一致。
有趣的是,一些榜单甚至使用了相同的评测集,但排名结果依然差异很大。就像是同一批运动员们换了个场地跑步,成绩排名却迥然不同。那么问题到底是出在运动员,还是在发令枪?
两个维度评价大模型
自ChatGPT问世到百模大战,8个月以来,评价一款大模型有两个公认的显化标准:一是参数量,二是评测集。
参数量指模型中可学习的参数数量,包括模型的权重和偏置。参数量的大小决定了模型的复杂程度,更多的参数和层数,是大模型区别于小模型的标志性特点。2022年,美国一批大模型亮相,从Stability AI发布由文字到图像的生成式模型Diffusion,再到OpenAI推出的ChatGPT,模型参数规模开始进入百亿、千亿级别时代。
从表面指标看,千亿参数的模型普遍比百亿级表现更好。不过也有少量例外,而且同样参数级别的模型应该如何分辨优劣?这就需要引入大模型的第二个评测维度:评测集。
所谓评测集,是为有效评估基础模型及其微调算法在不同场景、不同任务上的综合效果,所构建的单任务或多任务的统一基准数据集,有公开和封闭两种形态。
这些评测集就像针对不同领域的考卷,通过测试大模型在这些“考卷”中的得分,人们可以更直观地比较大模型的性能高低。
在小模型时代,大多数模型机构都会使用学术类评测集效果来作为评判模型好坏的依据。现在,大模型厂商也开始更加主动地参与到学术界基准测试框架中来,视其为权威背书与营销依据。
比如Meta发布开源大模型LIama2之际,就在相关技术论文里明确介绍了其于多个学术评测集之上的表现,并公开了在GSM8K和MMLU两款评测集上与闭源GPT-3.5的对比结果。
目前,国际上用的较多的大模型评测集是MMLU。它源自伯克利大学,考虑了57个学科,容纳了从人文到社科到理工多个大类的综合知识能力,被直接用于GPT-3.5、GPT-4和PaLM系列大模型的研发过程,国内科技大厂大多数情况也都基于这个框架进行评测。
商汤在发布最新财报时,专门介绍了新模型InternLM-123B在将近30个学术评测集上的表现,也将MMLU的评测成绩放在首位,并跟Meta的llama2做了横向得分比较。
之后,学界、产业界、媒体、智库、社区以及传统ICT(信息通信技术)分析机构都敏锐地捕捉到了这一行业热点,陆续在今年上半年推出了各自的大模型评测榜单。

**是市面上活跃的评测集/框架 ***为经典学术评测集/评测框架
根据界面新闻的了解,在目前已有的大模型榜单之中,UC伯克利主导的LMSYS是英文界最有影响力的大语言模型榜单,中文界目前则存在多个影响力接近的榜单,哪个榜单最佳尚无定论。
“评测是直观体现大模型能力的关键方式之一,学术化的榜单和市场化的榜单都得到了大家的重视。”一位大模型厂商相关负责人告诉界面新闻记者,虽然各种大模型评测榜又多又杂,但他们必须重视自家产品在各个榜单的结果。原因很简单,它会影响企业客户的采购决策。
为什么不同榜单会有不同结果?
华泰证券前资深算法工程师邱震宇近期加入了新公司南京图灵人工智能研究院,负责大模型研究应用。今年以来,他深入探究了市面上大模型的各类评测集,综合比较了各家榜单结果。他告诉记者,现在并不存在一个公认有效的评测方式。
为什么同一个模型在不同评测中的得分差异很大?评测集的侧重点不同是最重要的原因。
C-Eval——一家由上交、清华和爱丁堡大学研究员推出的当红开源评测榜单,因每周都有全新的模型进入榜单,新晋大模型经常排在GPT4之前而被抬上风口浪尖。
“现在大模型对评测集的选择非常敏感,这种状态不太合理,也不太客观。”邱震宇认为,比如在C-Eval榜单上,即使某个大模型超过了GPT4,也不代表它在中文语言上的能力就比GPT4强,只能说在做题应试上更厉害。
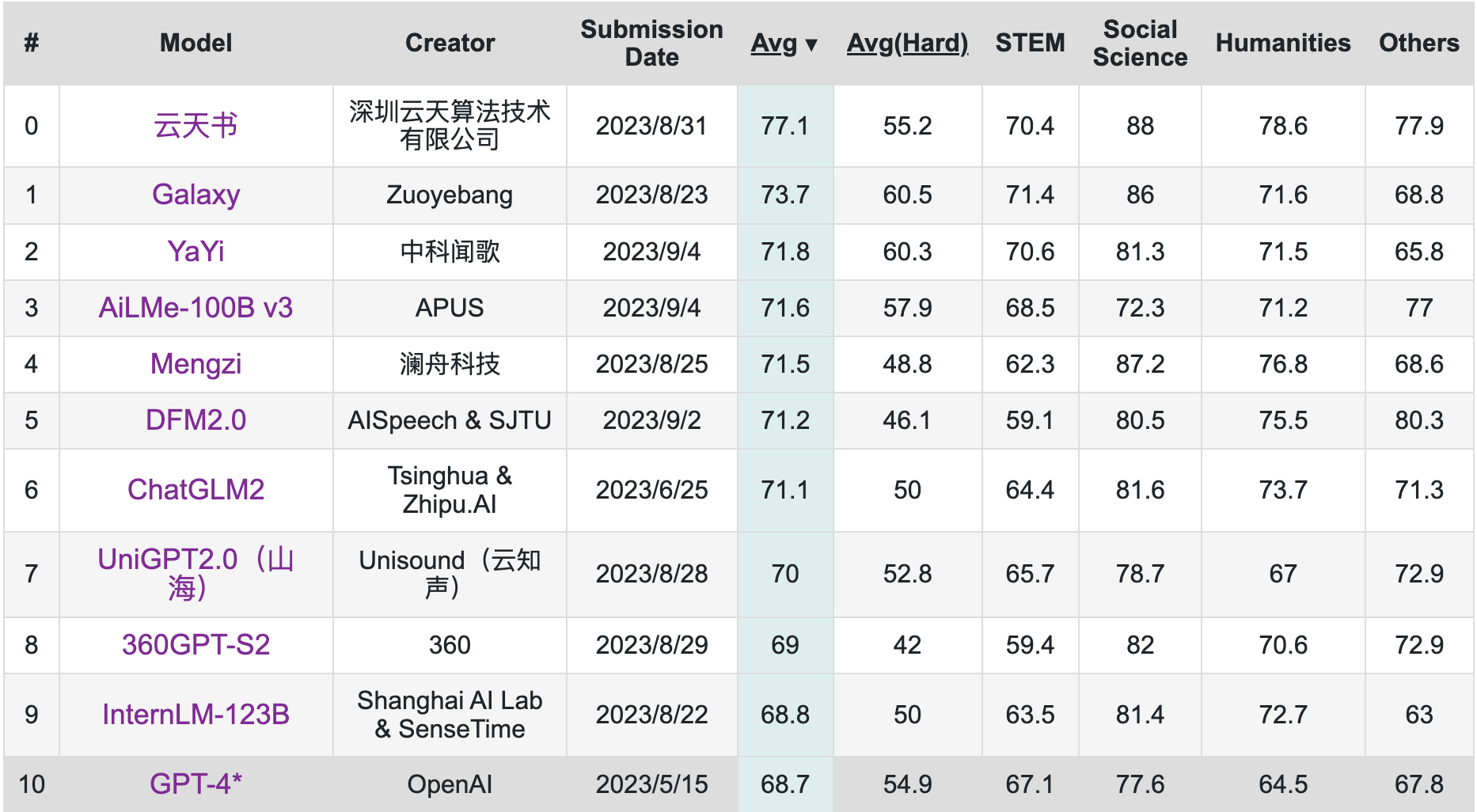
近期参与了很多评测工作的复旦大学计算机系教授张奇将C-Eval的问题归因为“评测从单点维度进行”,这是指每个流行学术评测集都有自己的侧重点。比如Meta最常选用的GSM8K和MMLU,是不同水平的考试集——前者是小学数学,后者则是更高级的多学科问答。
就像一个班的学生参加不同学科的考试,大模型们在不同榜单上自然排名不同。
主观题在大模型评测中比例上升也是导致评测结果差异的另一个原因。在现行海内外大模型评测榜单中,主观题与客观题结合的思路普遍被业内认可。
但主观题的挑战在于,每个人心中的评价标准是否一致。以及“人类团队评分”必然会触及题目数量的天花板,而对于大模型评测而言,题量越大得出的结论则越有效。
因此,业内也开始采用“人类+GPT4评分”的模式。国内如SuperCLUE会选择将GPT4视作“评卷老师”,让其加入人类团队辅助评分。
这一做法的背后存在着合理性支撑。3月,微软研究院发布文章称,类似GPT-4的强大LLM判别器可以很好地匹配人类偏好,达到超过80%的一致性,这是人与人之间的同级别的一致性。
此外,专用模型与通用大模型之间在垂直领域的同台竞技,是导致排名失真的另一原因。在实际落地场景中,制造业、医疗、金融等行业内企业客户在接入大模型能力时都需要根据自身数据库做二次微调。这也意味着,原版通用大模型直接参与垂直领域问答所得出的结果,并不能够代表大模型产品在垂直领域的真实表现。
榜单可以刷吗?
许多新晋大模型开始在类似C-Eval的榜单上排名超越GPT-4,揭示出开源评测集所引发的“作弊”现象。
根据界面新闻的了解,C-Eval目前只公开了题目但没有公开答案,参与测试的大模型厂商一般会采取有两种方式“刷榜”:第一种是找数据标注员把题目做一遍,第二种是用GPT-4把题做一遍,再把答案扣下来训练大模型,这样都能在相应学科测试中获得满分。
将评测题库“开源”的榜单将不得不面对大模型厂商“刷题”的做法,在某种程度上,是无法全面反映大模型真实能力的;而将评测题库进行“闭源”,虽然可以避免针对性刷题,但是对评测机构自身的权威性提出了更高的要求。
某清华系大模型初创公司技术相关负责人认为,倘若评测机构被认可是权威的,那闭源评测集更能反映相应语境下大模型的真实能力。
但闭源评测集也需要技巧才能规避“刷榜”。记者了解到,如果闭源评测集不进行更新换题,参与评测的模型可以从后台拉出历史记录进行“作弊”,重做被测试过的问题,这等同于“虚假闭源”。
来自智源研究院大模型评测组的李薇认为,刷榜现象从小模型时代就有,丰富多样的评测任务有助于全面了解模型,但“过多的榜单确实会增加研究人员和公众的理解负担,因此更亟需建立有公信力的榜单。”
随着各种各样的榜单越来越多,甚至有人质疑有些榜单可以直接花钱买排名,这让大模型评测榜的公信力进一步受损。不过,“花钱买榜”目前并无实锤,更多存在于竞品间的互相猜测中。
更好的评测需要什么?
“评测集应该是封闭的,避免被作弊,但一个好的大模型评测应该是过程公开的评测,方便大家对评测做监督。” 前述清华系大模型公司技术负责人表示。
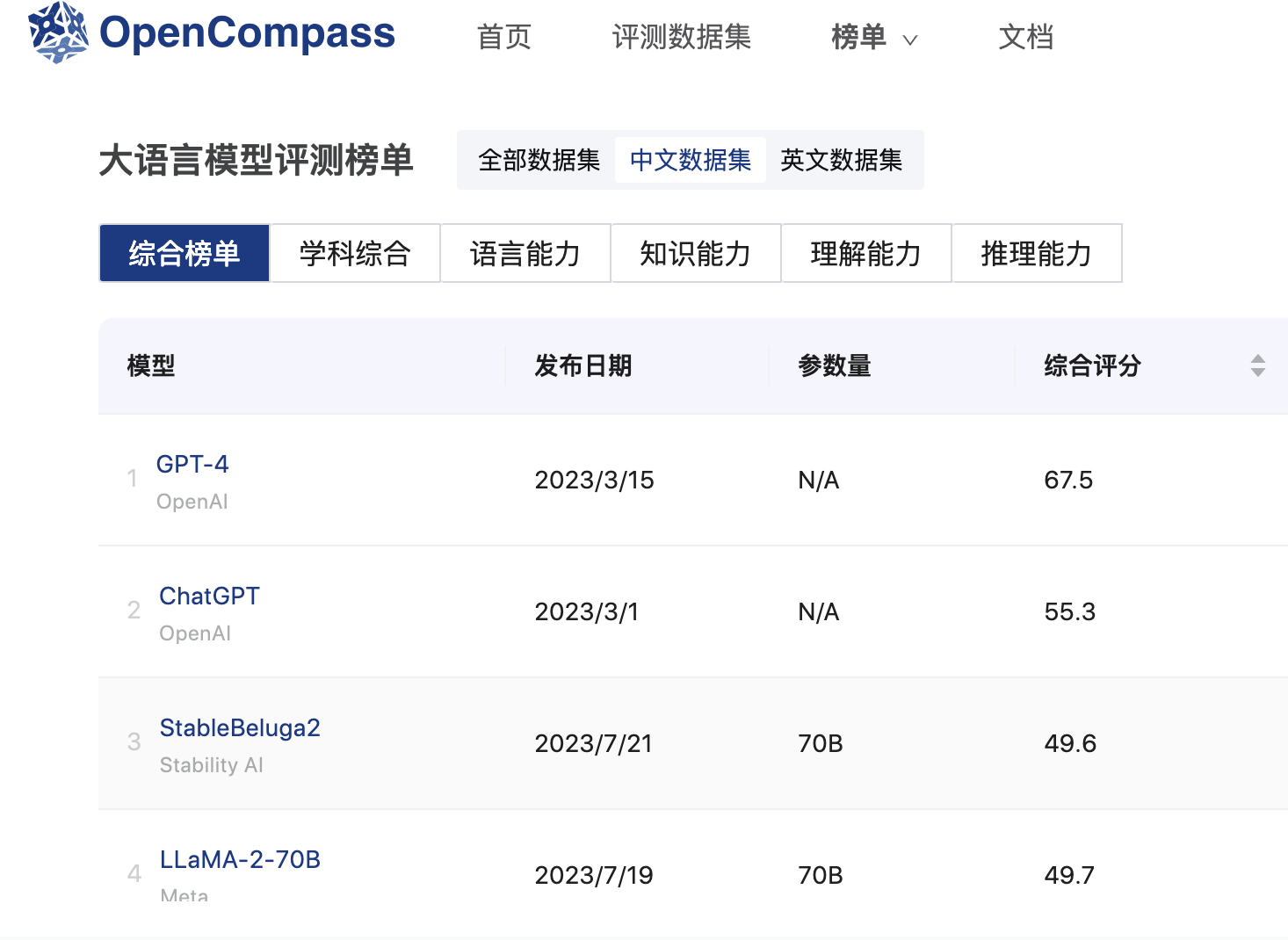
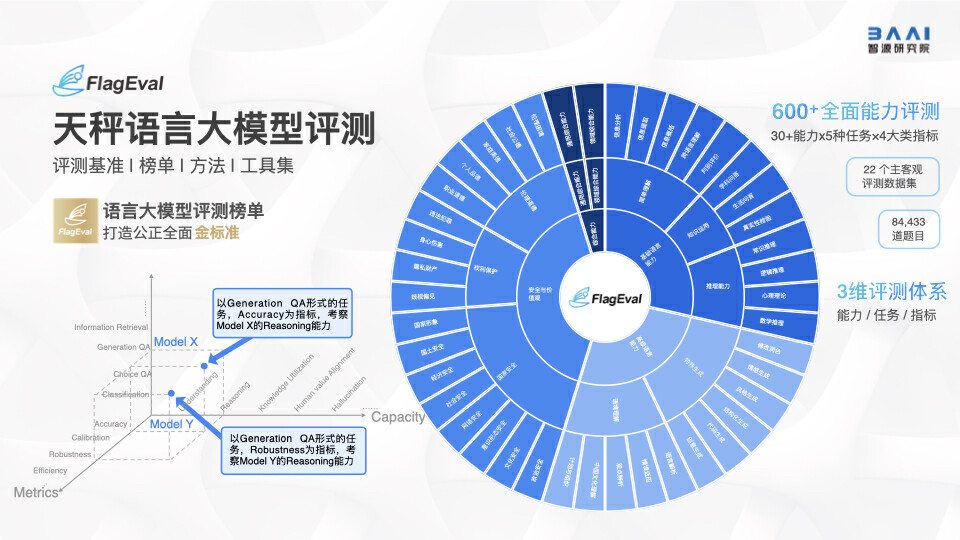
不过,目前国内绝大部分评测不能做到“过程公开”,只有两家除外,一是上海人工智能实验室的OpenCompass,其将完整的评测流程都通过代码开源出来,包括所用的数据集;二是智源研究院的FlagEval,没有开源评测代码,但也公开了所用的数据集。
智源大模型评测组研究员李薇告诉记者,将大模型评测过程公开是很好的愿景,但考虑到评测的公平公正性,还是应有大量的封闭评测集,“闭卷考试”才能真正的评价出模型的能力。智源自有FlagEval平台就要求把待测模型部署在平台自有的服务器后再进行评测,从根源上避免了作弊和评测数据的流出。
几乎所有业界受访者都对界面新闻表示,未来更看好OpenCompass和FlagEval这样具有一定学术背景的评测机构模式,原因之一是OpenCompass和FlagEval自带算力资源,可以支持每次大模型评测;其二是OpenCompass是少见的大型综合性榜单,纳入了全球业界50余个评测集,提供了30万道题目,FlagEval也包含了8万+道题目,还把对模型潜力的指导纳入体系中。
但FlagEval和OpenCompass的模式也只是一种初探,关于如何作出真正综合全面的大模型评测,学界和产业界最前沿也呈“一头雾水”。
参考谷歌、微软、斯坦福大学、牛津大学、OpenAl等机构的研究,他们暂时将大模型评测技术按评测维度分为:模型性能、模型泛化能力、模型鲁棒性和安全性、模型能效等。
但界面新闻记者了解到,目前各大学术类榜单的评测基本围绕模型性能和泛化做文章,他们会在评测中将这些维度转化为大模型的“准确性”指标,比如知识理解、知识推理、阅读理解、知识问答、代码生成等细分类目,再通过学术考试的方式评估,但鲁棒性、安全性、效率等等影响大模型落地的维度很少能在榜单上真正体现。
邱震宇观察到,安全评测目前很难设计出可量化的方案,而“有能力做这块评测的人,除了要懂大模型,也要懂社会工程学和心理学。”
“仅仅使用学术评测集是不够的,无法全面反映用户的实际需求和实际体验,需要对学术评测集进行一定程度的改造,使其更贴近用户真实的使用场景。”深度参与了FlagEval评测工作的李薇补充称,大模型评测还一定程度上应将用户体验纳入考察范围。
在更为有效、更被认可的评测方式问世之前,大模型评测榜“各说各话”将会持续很长时间,厂商也势必会主动或被动地参与到各类榜单中来。
不过,归根结底,榜单只是工具,市场才是目的——谁能提供更贴近用户需求的产品,满足更多企业和个人的需要,谁才是“最优秀”的大模型。
(应采访者要求,文中李薇为化名。)
